
Evals from scratch: Building LLM evals with aibff from Markdown and TOML
From manual grading to autonomous evaluation
If you liked it then you should’ve put a test on it.
- The Beyonce Rule
Evals are the most annoying part of AI engineering. They’re hard to set up, require regular maintenance, and break when you change your prompts, forcing you to rebuild them from scratch just when you need them the most.
We’ve built a reliable system for evals using nothing but Markdown, TOML, and a simple command-line tool.
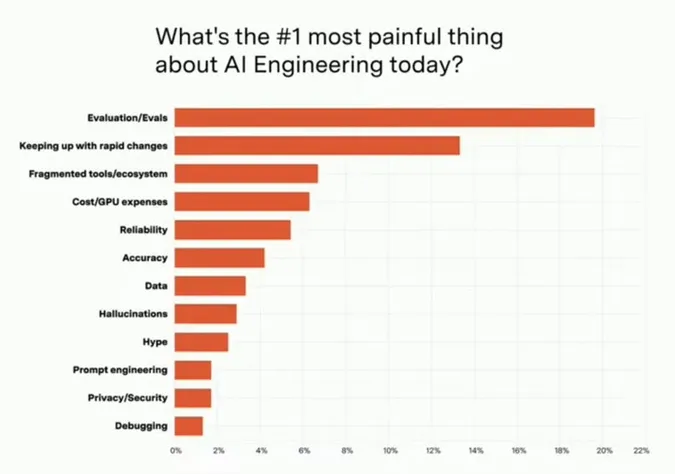
Source: PromptLayer
Years ago I built a weekly sports text message service for people who don’t follow sports. I curated and texted the biggest headlines of the week to keep people updated in 30 seconds. I stopped because the manual process was tedious, but with AI, I can now automate the whole process.
Last week I revived and rebuilt the service as an AI tool, turning rote research and summarization work into an automated process.

But moving from human-written content to AI creates a lot of pitfalls.
This gave us a perfect test case for our eval system. Instead of rebuilding evals from scratch every time we tweaked the prompt, we needed something that could adapt and improve. Here's how we solved it.
Baby’s first eval 🐣
The app works by scraping sports news from the last seven days. An LLM then picks the top five stories and writes a one-line summary of each for the weekly text digest.
We started by taking our existing prompt and asking an LLM what dimensions we could grade on. Of the identified parameters (tone, quality, story selection, and length), we decided to build our first eval for story selection.
The first step is to collect and rate samples to build our grader.
With Fastpitch, we pulled the most recent “digests” of five stories, and graded them by hand on a scale of -3 to +3. We call this process Reinforcement Learning from Hotdog Fingers (RLHF). These are the “Ground Truth” samples that inform the Grader.
Because we didn’t have enough samples for every point on the scale, we uploaded a CSV of ~80 stories and asked Claude to create synthetic samples for the missing values.
With our
truth.deck.toml
and
syntheticSamples.deck.toml
files in place, we were ready to create the Grader.
To get a baseline grader for the story selection dimension, we simply referenced our sample deck and asked Claude to build a grader that evaluates samples specifically for relevance.
Voila! We created a Grader based on sample data.
Running the first test 👩🔬
With our baseline grader in place, we were ready to run our first eval with aibff, a command-line tool we built that runs AI evaluations against sample data using simple Markdown configuration files.
aibff calibrate apps/aibff/decks/fastpitch/sports-relevance-grader.deck.md --output tmp/results --model openai/gpt-4o,openai/gpt-4.1
This gave us our first real results!
…which were not great. But that’s fine!
Because we could iterate and refine the Grader until it performed the way we expect.
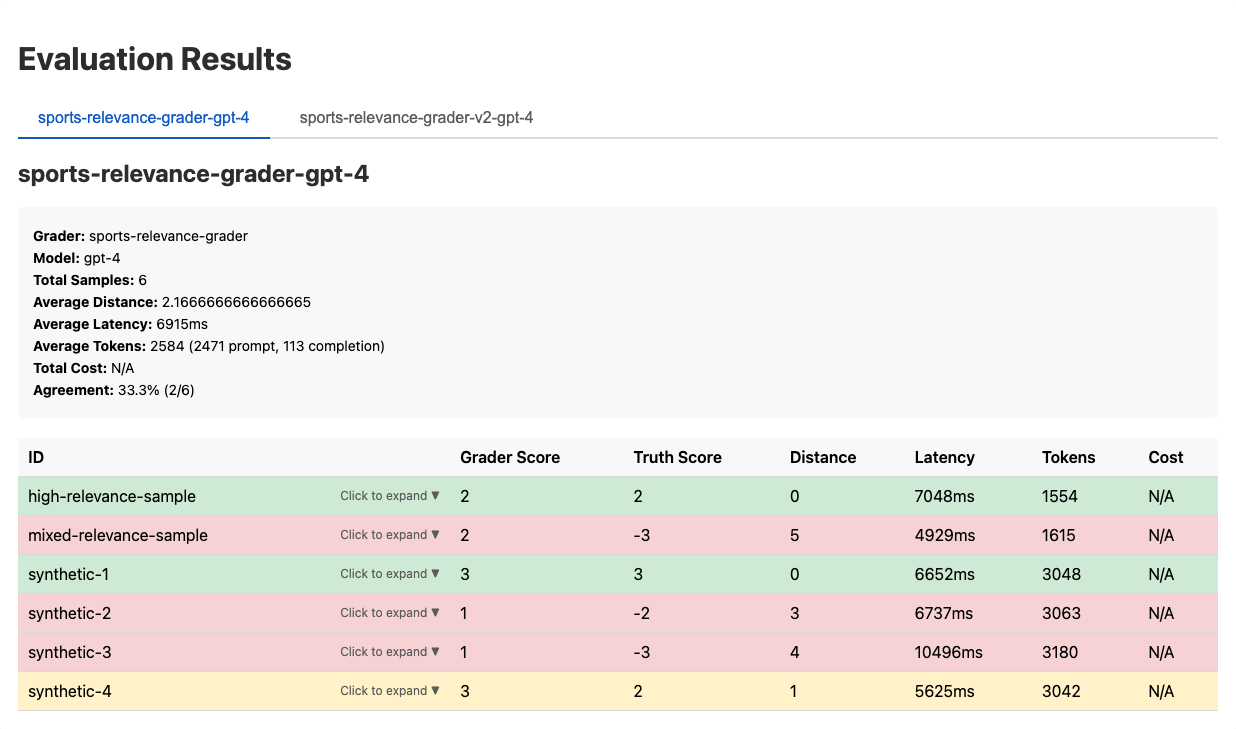
With a results.html file with real data, we can ask Claude to review and bring
the Grader in line with the Ground Truth Score. For Fastpitch, we pointed Claude
to results.html and asked it to look for inconsistencies between the Grader
and Ground Truth samples, and to update the Grader accordingly.
In this case, we created a Grader-v2 to measure changes against a baseline. After a few (dozen) iterations and refinement, we ended up with a Grader that agreed with the Ground Truth scores 100% of the time using both GPT-4o and GPT-4.1.
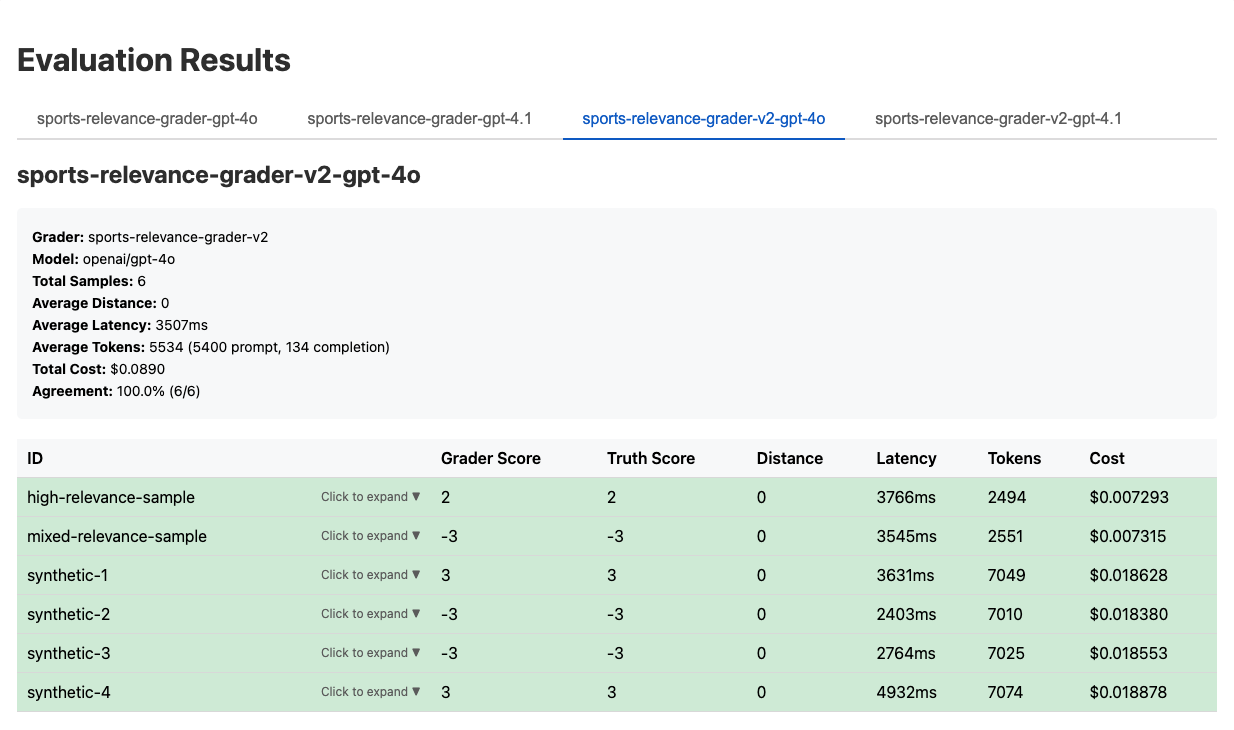
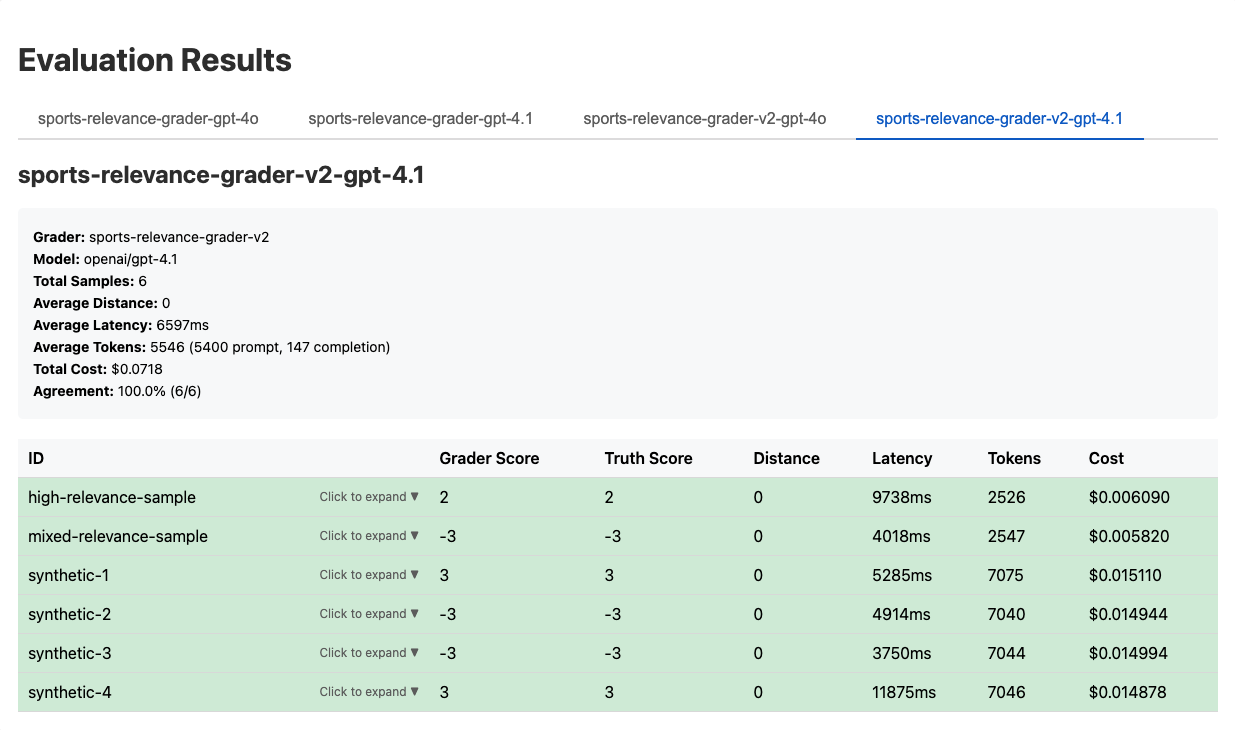
What's next?
With a performant grader in place, there are two directions we can go:
- Identify another dimension to grade on and run the process again. Ultimately we want to end up with a discrete Grader for every dimension that’s important to our prompt.
- Use the Grader and sample data to update our prompt.
For Fastpitch, we’ll build graders for all four dimensions until we’re happy with the stories output every time. Then we’ll use those Graders to modify our base prompt.
Our team is continuing to build tools that make it easier to add advanced debugging capabilities to LLM apps, and optimize prompts.
We’re looking for people who want to learn more about evals and build prompts scientifically. If that sounds like you, join our community on Discord.